
Ambisyllabicity and syllable overlap
Phonetic interpretation in YorkTalk/IPOX is compositional, that is, polysyllabic words are made up from their individual syllables. As a consequence, there are no separate rules for intervocalic consonant clusters.
Ambisyllabicity is used to assure that intervocalic consonants are properly coarticulated with their neighbouring vowels. That is, in a word such as /bot@l/ the /t/ should be interpreted:
- as a coda with restect to the preceeding vowel
- as an onset with respect to the following vowel
Thus, the intervocalic /t/ must be parsed as a coda of the first syllable, and as an onset of the second syllable:
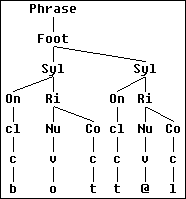
In phonetic interpretation, the onset is overlaid on the coda of the previous syllable. Different amounts of overlap are used in different contexts (Coleman 1995):
- very short closure ("flapping")
--Vowel-|-Closing-|---Closure---|-Release-|---
-Closure-|-Release-|-Vowel-- - normal intervocalic closure
--Vowel-|-Closing-|---Closure---|-Release-|---
-Closure-|-Release-|-Vowel-- - long closure ("gemination")
--Vowel-|-Closing-|---Closure---|-Release-|---
-Closure-|-Release-|-Vowel--
Example
The following rule is used to generate the correct amount of overlap for ambisyllabic /t/ in /bot@l/:
cons:[+coda, VOICELESS, -cnt, -nas, str=A, cns=B, squish=C]
+
cons:[-coda, VOICELESS, -cnt, -nas, str=A, cns=B]
=>
C * (250 - A*50) + 140.
In this rule, the feature squish encodes the amount of compression assigned to the first syllable.
Ambisyllabicity is not restricted to single intervocalic consonants (as in most phonological theories). Within (latinate parts of) words, intervocalic clusters are parsed with maximal ambisyllabicity:
By parsing the bracketed clusters as ambisyllabic, we derive that:
- in each of these cases the first syllable is heavy
- the /t/ in /wint@r/ is aspirated, but in /sist@m/ it is not aspirated, as it occurs in an onset cluster /st/
Implementation
- In YorkTalk, consonants are made ambisyllabic through overparsing (parsing without consuming input)
- In IPOX, overparsing is not allowed, so at the moment ambisyllabic consonants must be spelled out twice in the input
As a more principled solution, we are presently experimenting with a "head first" parsing algorithm adapted from Van Noord (1993):
parse(Input, L, R, Target) :-
head(Target, Head),
input(Head, Input, L0, R0),
head_first(L0, L, R0, R, Head, Target).
head_first(L0, L, R0, R, Head, Target) :-
Phrase --> (NonHead / Head),
parse(L0, L1, [], NonHead),
head_first(L1, L, R0, R, Phrase, Target).
head_first(L0, L, R0, R, Head, Target) :-
Phrase --> (Head \ NonHead),
parse(R0, [], R1, NonHead),
head_first(L0, L, R1, R, Phrase, Target).
head_first(L0, L, R0, R, Head, Target) :-
Phrase --> Head,
head_first(L0, L, R0, R, Phrase, Target).
head_first(L, L, R, R, Target, Target).
input(Head, [Terminal|L], [], L) :-
lex(Terminal, Head).
input(Head, [Terminal|L1], [Terminal|L2], L3) :-
input(Head, L1, L2, L3).
This parsing algorithm has the following properties:
- it is a "greedy" algorithm, that is, it tries to parse as much of the input as is allowed by the grammar
- the parse tree is constructed bottom-up, starting with the head of a constituent
We plan to use this algorithm in the following way:
- syllables are constructed using the head first algorithm
- between syllables we allow overlap
Examples
- /wint@r/ is parsed as /wint/+/t@r/
- /asprin/ is parsed as /asp/+/sprin/
- /sist@m/ is parsed as /sist/+/st@m/
Also:
- /aspsprin/ is parsed in the same way as /asprin/
- /asprsprin/ is rejected as /r/ remains unparsed