A finite state machine (FSM) (or finite state automaton) is an abstract
computing device consisting of:
a set of states
some of which are distinguished as start states
some of which are distinguished as end states
a set of labelled transitions between states.
We can draw an FSM as a network of nodes (representing states) joined by arrows (representing moves allowed from one state to the next), like this or this.
A finite state machine accepts a string if it is possible to trace a path
from a start state to an end state, reading off the labels on the
transitions as they correspond to successive symbols in the string. FSMs
can thus be used as a pattern matching technique.
Alternatively, it is possible to generate the set of strings acceptable to
an FSM by writing the transition labels in succession.
A simple implementation of the example is given in nfsa1.pl.
In this Prolog code, strings are represented as lists of symbols e.g. [s,p,r,i,n,t]. A transition from state n to state m accepts the letter "s", for example, if the portion of the string remaining to be analyzed at state n is [s | Rest of string] and the remainder of the string at state m is just "Rest of string". An end state is said to be accepting if and only if none of the string remains to be analyzed i.e. Rest of string = [].
Download and save nfsa1.pl to your laptop
Start Prolog
At the prolog prompt ?-
type
[nfsa1].
To see if the string [s,t,r,i,n,g]
is acceptable, type
accept([s,t,r,i,n,g]).
To nondeterministically generate an acceptable string, type
accept(X).
After the first answer is generated, additional solutions may be generated
by typing a semicolon. To generate all of the acceptable strings, type
loop.
(That's not a built-in Prolog function, but one defined in the program.)
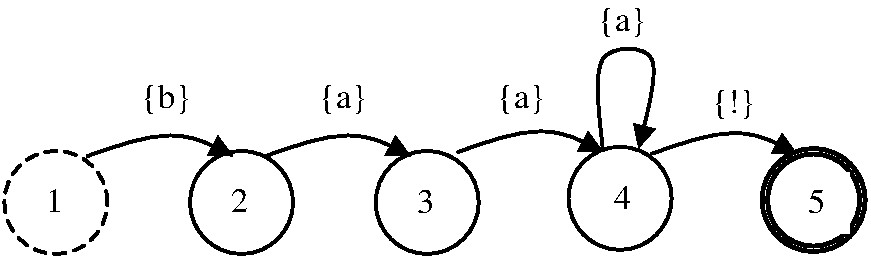
Symbol state table for FSM1.
Although there are no examples in FSM1, a transition may map a state onto
itself i.e. the state is not changed even though the input symbol is
acceptable. A "searcher" is an FSM with just two states, like this.
The machine stays in the first state if any symbol other than a particular
search symbol is read. If the search symbol is found however, a transition
to the second state occurs. The machine stays in the second state whatever
other symbols are read in. The second state is final, so if the string
ends at any point after the search symbol has occurred, the input is
acceptable. If, however, the search symbol does not occur in the input
string, the end state will never be reached and so the input string cannot
be accepted.
From a given state, and with a given remaining string, if there is only one possible transition that can be taken, the machine is deterministic. FSM1 is non-deterministic because from some states there is a choice about which transition to follow. Computers cannot make choices, so faced with this circumstance they can only explore every possible option in turn. (That's what happens during the execution of the "loop" command.) Deterministic FSMs are sometimes more efficient than non-deterministic ones.
Transitions may be labelled with pairs of symbols, not just one symbol. A
finite state machine of this kind is called a finite state transducer, and
works with two strings at a time. A transition is acceptable if one
element of the label is the first symbol of one string and the other
element of the label is the first symbol of the other string. In this way,
correspondences between the symbols of one string and symbols of the other
string can be related to another in sequence. One example of such a device
computes grapheme to phoneme relations. Transition labels such as
ph:f
th:T
th:D
sh:S
c:k
k:k
ck:k
sch:sk
oo:U
oo:uw
x:ks
will be found in such a machine.Since there is no formal instantiation of
structural constituency in finite-state machines, wider contexts have to
be implemented by using (possibly large) sets of multi-symbol relations,
e.g.
ane:eIn
ame:eIm
ape:eIp
etc.
nfst1.pl lists an example of such a transducer.
Try it out:
?- [nfst1].
?- accept([s,q,u,e,a,k],_).
?- accept(X, [f,'0',k,s]).
The symbols on transition labels need not be letters of the
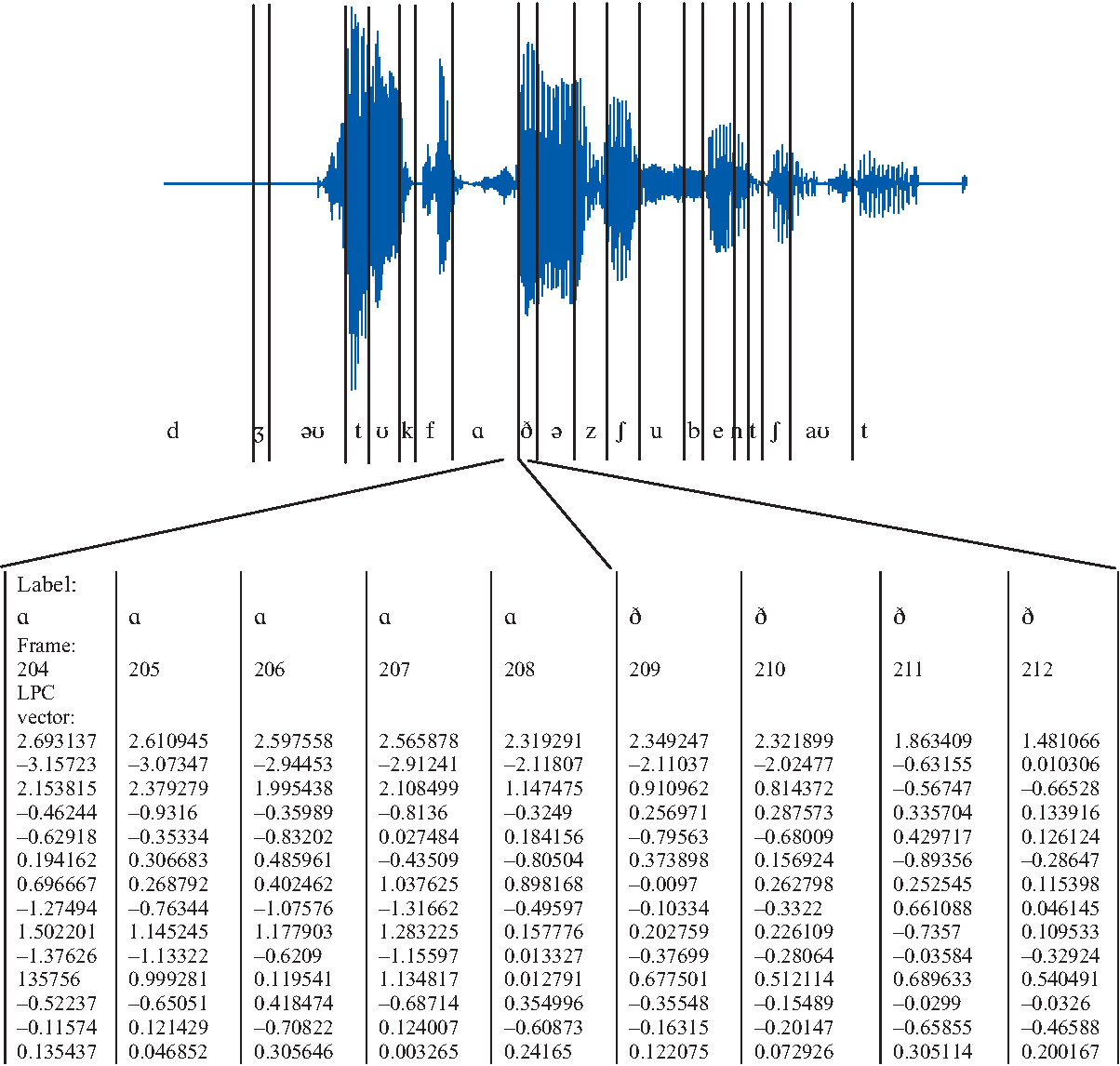
alphabet: any symbols will do. For instance, we could take vectors of
acoustic analysis parameters (for instance a set of LPC predictor
coefficients) as symbols. The alphabet of such symbols will be very large,
but finite nonetheless. If we have a phonemically labelled speech
database, we could relate phoneme symbols to analysis vectors, like this.
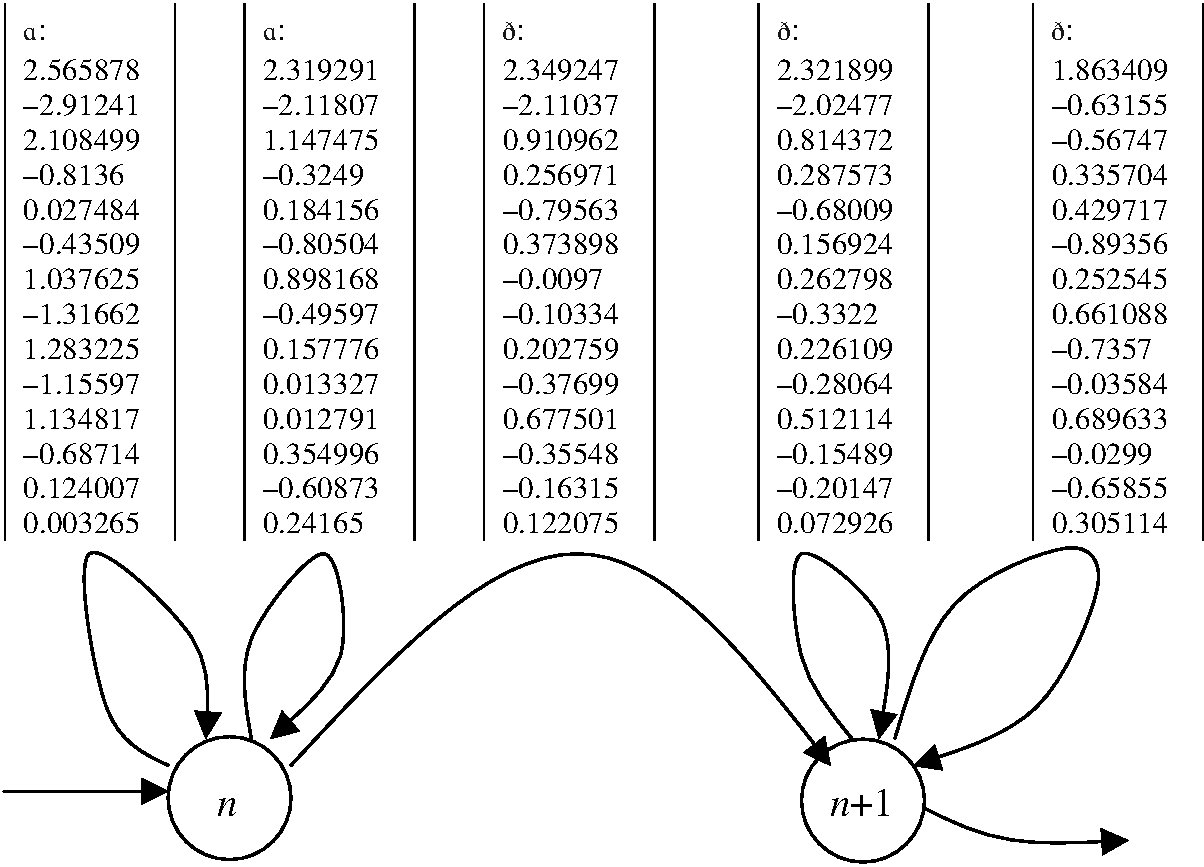
Changes from one vector to another within a phoneme can be modelled as
self-loops with phoneme:vector labels, like this.
Changes from one vector to another at phoneme boundaries will be modelled
as state-changing phoneme:vector transition labels. In a later seminar we
shall see how large phoneme:vector finite state transducers can be
constructed automatically from a labelled speech database. We could use
such a machine for speech analysis (automatic segmental labelling or part
of a speech recognition device) or for generation (synthesis). The main
practical problems lie in the size of the machine needed in order to cover
the space of analysis vectors fully.
Finite state transducers have also been employed extensively in modelling
SPE-type rule systems, subject to certain common restrictions (see Kaplan
and Kay 1994 and references), as well as in computational implementations
of autosegmental phonology (see Bird and Ellison 1993 and references).
Finite-state syntactic processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}