(After Young et al. 1997)
Let each spoken word be represented by a sequence of speech vectors or observations O, defined as
O = (o1 o2 o3 o4 o5 ... on )
where ot is the speech vector observed at time
t.
The isolated word recognition problem can then be regarded as that of
computing
| arg | max | {p(wi | O)} |
|
|
(which means "the word wi for which the probability of that word's occurrence given the observation sequence is maximum"). So, wi is the i'th word in the dictionary, and p(wi | O) is the probability of wi being the right word, given O. This probability is not computable directly, but, according to Bayes' Rule, we have:
| p(wi | O) = | p(O | wi ) p(wi
)
|
p(wi ) is referred to as the prior probability that of word wi 's occurrence. It is related to that word's frequency of occurrence in some domain. It is normally estimated on the basis of the preceding sequence of words, using another probabilistic finite-state automaton, grandly termed the language model, such as this.
p(O), the observation probability, is 1, because the observation sequence is known. Hence, p(wi | O) depends only on p(O | wi ). That is why we use an HMM which is a generator of speech vectors, as in figure 7.6: to estimate p(O | wi ). Given a set of models Mi, corresponding to words wi, we assume that
p(O | wi ) = p(O | Mi ).
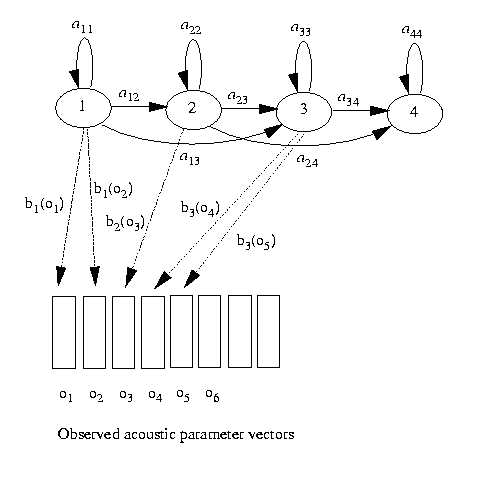
For a particular state sequence X in figure 7.6
p(O, X | Mi ) = a01b1(o1) × a11b1(o2) × a12b2(o3) ...
However, only the observation sequence is known: the underlying state sequence X is hidden. That is why it is called a Hidden Markov Model. Given that X is unknown, the required likelihood is computed by summing over all possible state sequences. Alternatively, the likelihood can be approximated by considering only the most likely state sequence.
All this, of course, assumes that the state transition probabilities aij and the observation probabilities bj (ot) are known for each model. Herein likes the elegance and power of the HMM framework: given a set of training examples corresponding to a particular model, the parameters of that model can be determined automatically.
{kind=link}
{kind=link}