
Word joins in real-life speech: a large corpus-based study
Research funded by ESRC award RES-062-23-2566
The original Case for Support from our application to the ESRC can be read at http://www.phon.ox.ac.uk/jcoleman/WordJoinsCaseForSupport.pdf.
Co-Investigators: John Coleman, Ros Temple, Jiahong Yuan (UPenn). (Greg Kochanski was also one of the original co-investigators, but he's moved to another job now.)
Research Associates: Ladan Baghai-Ravary, Peggy Renwick
Research IT Support: John Pybus
In this research project, we are studying how words are joined together in natural, fluent, everyday speech. In particular, we carried out detailed acoustic measurements of numerous recordings to see (a) how English speakers change the last consonants of words to link them up to the next word, and (b) when and in what circumstances people "drop" final 't's and 'd's. The recordings we use are from thousands of naturally-occurring conversations collected in the 1990's for the British National Corpus, which we have digitized and partly aligned with transcriptions in previous projects. In order to search for and find specific portions of speech, we use automatic speech recognition technologies. The methods we have developed should help future work on searching and finding tools for audio-visual data, such as sound libraries, movie databases etc. This opens up the audio recordings from the British National Corpus for other researchers - and anyone interested in English speech, not just academics! - to find whatever they may be looking for in that vast collection of recordings.
Our study is loosely parallel to Dilley and Pitt (2007) who studied American English to answer somewhat different research questions.
Consonant place assimilation
According to many handbooks and textbooks on English phonology, word-final alveolar consonants (i.e. /t/, /d/, /n/, /s/ and /z/) - and only alveolar consonants - change their place of articulation to match the consonant with which the next word begins. Dilley and Pitt (2007) studied the incidence only of theoretically allowed alveolar assimilations, like:
- "ran quickly" → "ra[ŋ] quickly"
- "that case" → "tha[k] case"
- "bad case" → "ba[g] case"
- "this shop" → "thi[ʃ] shop" (cf. "fish shop")
Such assimilation also occurs word-internally, e.g.:
- "incompetent" → "i[ŋ]competent"
- "input" → "i[m]put"
- "infer" → "i[ɱ]fer" (somewhat like "imfer")
- "his shop" → "hi[ʒ] shop
- "ungodly" → "u[ŋ]godly"
- "unbecoming" → "u[m]becoming"
- "envy" → "e[ɱ]vy"
In English, assimilation of labial or velar consonants should not happen, according to the textbook rule. Thus, pronunciations such as "ki[m]pin" for "kingpin" or "alar[ŋ] clock" for "alarm clock" would be counterexamples to the general rule. If more counterexamples are found than can be explained as speech errors, the rule would need to be questioned or modified. Therefore, in contrast to Dilley and Pitt, we will also search for instances of assimilation in the theoretically forbidden cases. The allegedly forbidden assimilations are found in other languages (e.g. German: Zimmerer et al. 2009; Diola-Fogny, Korean: Jun 1995 ch. 2), so they are certainly linguistically possible articulations. If they are not found in English, it can only be because some language-specific constraint(s) forbid them. Theory notwithstanding, there is some evidence that such violations occur. Barry (1985) has attested to "like that" → "li[t]e that”, and Ogden (1999:74) attests to "I'm going" → "I'[ŋ] going", both involving final consonants that are not alveolars. Pronunciations of some expressions, such as "I'm gonna" and "alarm clock", with a velar nasal (i.e. [ʌŋənə] and [əlɑːŋklɒk]) are encountered quite frequently in casual listening and are well attested in speech corpora. For example, here is an .avi video clip from a news report in which US President Barack Obama is saying "I'm gonna c[onvince]":
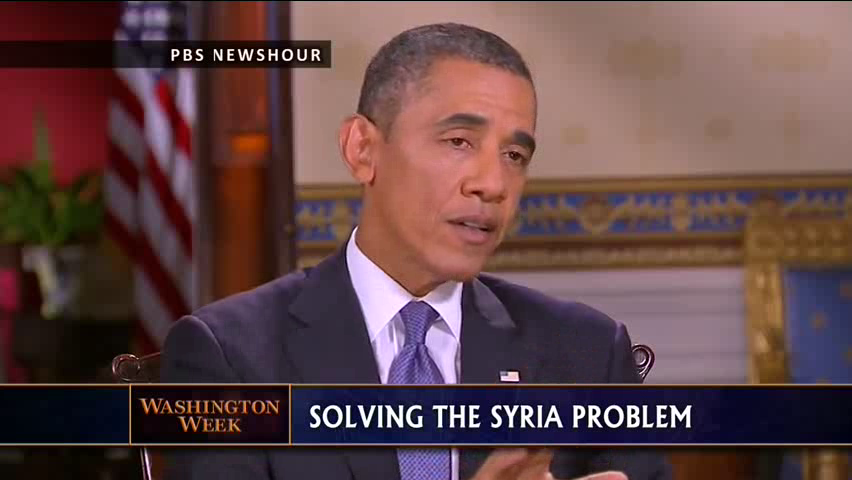
(Source: PBS Newshour/Youtube TIP: if the clip does not play well within your browser, because it is so short, feel free to save it to your local disk and then play it using another video player.)
The still photograph to which the video clip is linked is one of four video frames in which he articulates the medial [ŋ] of [ʌŋənə]. In all of those frames, it is quite evident that his lips never close, as they should for an [m]; there is no [m] in this token of "I'm".
There are also suggestive spelling mistakes like "sonetimes" (i.e. "sometimes") (200 ppm in Google) or "tinetable" (i.e. "timetable") (74 ppm in Google), in which a bilabial nasal seems to have assimilated to a following alveolar, or "Washinton" (for "Washington") (2093 ppm in Google), in which a canonically velar nasal is spelled as if it were alveolar. These might simply be spelling mistakes, but our study reveals whether such assimilations actually occur in speech.
However, the observations given above and in our orignal grant proposal are anecdotal, with no context, no audio available for detailed study, and no statistics on their frequency of occurrence. Thus it is important to establish whether non-alveolar assimilations occur in natural speech, their incidence, and (assuming they exist) the patterns of violation, the contexts in which they occur, and the sociolinguistic factors governing them.
Variable word-final (t/d) in spontaneous speech in UK English varieties
The project will also enable us to test on a large scale a very well-known sociolinguistic variable which occurs at word endings. Variation in the presence of word-final final /t/ or /d/ in a consonant cluster (first studied as a sociolinguistic variable by e.g. Wolfram 1969) is a very common phenomenon, especially in rapid or informal conversational speech. The following phonological context has consistently been found to be the strongest factor in determining the probability of deletion. Guy (1991) described the process in terms of the theory of Lexical Phonology. In his account, the past tense of a word is constructed in up to three stages and at each stage, a probabilistic deletion rule is applied. According to this account, monomorphemic words ending in [t] or [d] (e.g. “mist") have three chances at deletion, strong verbs where the final t/d is generated as the past-tense is formed (e.g. “kept”) will have the rule applied only twice, or just once if they are weak verbs (e.g. “stopped”). Tagliamonte and Temple (2005) found this pattern did not hold in a sample of 40 speakers from the York Corpus, and further qualitative investigations by Temple (2009) and Temple (2014) suggest that it may be more appropriate to treat so-called t/d deletion not as a (variable) phonological rule, but as a phonetic (continuous) speech process. The size and nature of the spoken part of the BNC and the techniques we have developed will allow us to reinvestigate the process on a large scale.