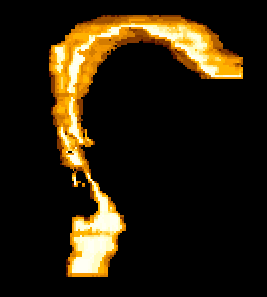
Figure 1: Vocal tract profile of [æ].

1. n-section models of the vocal tract
The actual profile of the vocal tract bears little resemblance to the two-tube models considered in the previous lecture. For example, fig. 1 shows the actual volume profile of a male speaker's vocal tract articulating the vowel [æ]. (The figure is computed from MRI scans, and was obtained from Brad Story's website.)
|
Figure 1: Vocal tract profile of [æ]. |
|
In an attempt to model such profiles more accurately, we can examine
the resonances of many concatenated tubes. Figure 2 shows an arrangement
of eight tubular sections, and figure 3 the area function of that model:
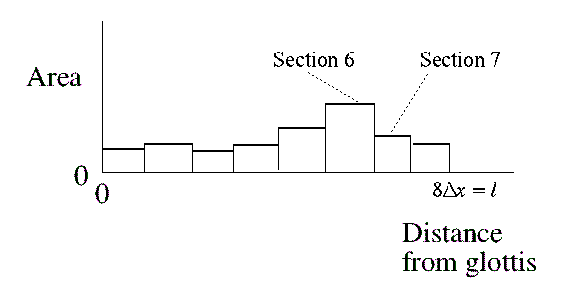
Figure 3: Area function of eight section model |
2. Pressure waves in a 2-section model
We consider the transmission of a wave travelling from the glottis to the lips. Also, because of the steps in the area function, some of the energy is reflected back down the vocal tract. There is also a net "echo", a wave travelling from the lips back to the glottis. Consequently, the pressure P in any section is considered to be made up of two components, a forward wave P+ and a backward wave P- (figure 4). Thus, P = P+ +P-.
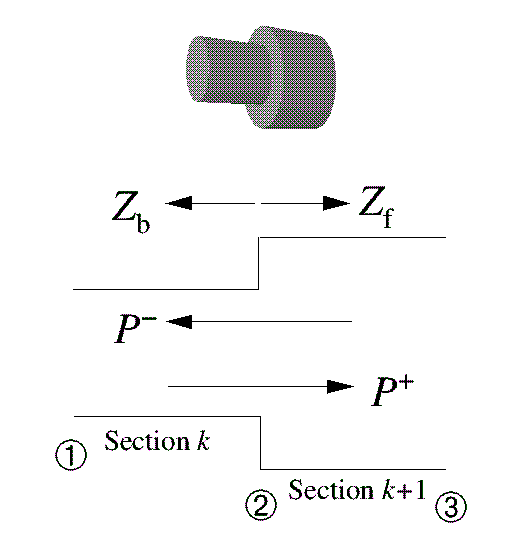
Figure 4: The interface of two tube sections |
Consider what happens at the interface between one tube section and the next (e.g. sections 6 and 7 in figure 3). Each tube section has a characteristic impedance (akin to a resistance to airflow). In figure 4 the impedance forward of the interface (point 2) is labelled Zf and the impedance of the section behind the interface is labelled Zb. The forward wave is partly propagated and partly reflected. The reflected fraction rP+ now becomes part of the backward wave, and the propagated part continues forward. The factor r is called the reflection coefficient, and is defined as:
(1) r = (Zf - Zb)/(Zf + Zb)
Note that r is between -1 and 1. At the interface, P+ is continuous, hence the propagated fraction must be (1+r)P+, so that:
(2) P+ = (1+r)P+ - rP+.
Exactly similar considerations apply to the backward wave P-, except that since it travels in the opposite direction Zf and Zb are reversed. Thus the reflection coefficient to the backward wave is:
(3) (Zb - Zf)/(Zb + Zf) = -r
The propagated part of P- is therefore (1-r)P-,
and the reflected part is -rP-. In this case the reflected
fraction adds to the forward going wave. This situation is illustrated
in figure 5:

Figure 5: Reflection relationships at an abrupt discontinuity in an acoustic tube |
If there are no losses in the tube the acoustic impedances Zf and Zb are simple functions of the cross-sectional area A(x): Zf = DV/Af and Zb = DV/Ab, from which we can work out that:
(4) r = (Ab - Af)/(Ab + Af).
(In practise, we can also obtain the reflection coefficients by using
linear prediction software, such as the xwaves program refcof.)
3. Pressure waves in an n-section model
In a model with n sections, where there are multiple discontinuities, there will be multiple reflections. It is therefore necessary to consider the pressures at discrete points in time, in other words, to consider the signal digitally. For the tube in figure 5, the P+ wave travelling from left to right will propagate undisturbed from point 1 until it reaches the discontinuity at point 2. Similarly, the backward wave P- will propagate from point 3 without reflecting until it gets to point 2. If the tube sections are of the same length, l, the time taken for P+ to go from point 1 to point 2 is equal to the time it takes for P- to go from point 3 to point 2, i.e. T = l/c, where c is the velocity of sound.
Thus the pressure variations at point 2 (and every other point) only need to be calculated at discrete time intervals, multiples of T. The sample interval T must be less than or equal to half of the highest frequency that it is desired to generate. For speech, the highest frequency of interest is about 6 kHz. Sampling rates of 11025 Hz and 16000 Hz are widely used for medium-quality digital recordings of speech. The sample intervals in these two cases are about 0.000091 s (91 µs) and 0.000063 s (63 µs) respectively.
The maximum section length l is also dependent on the sampling rate, since T = l/c. For a sampling rate of 11025 Hz, the maximum section length is 0.03084 m; for a vocal tract of length 0.175 m, a minimum of six tube sections will be required. WIth a sampling rate of 16000 Hz, the maximum section length is 0.02125 m, necessitating nine tube sections in the model.
In order to calculate the pressure at any of the junctions in the tube model (and in particular at the "mouth" end), it is necessary to know the pressure wave at the glottis (the closed end of the tube), expressed as a digital signal at time intervals T from 0 until some time later time nT, the end of the utterance to be generated. A counter is used to increment T to 1, and the forward and backward pressures calculated at each interface, according to the reflection coefficients and the equations given in section 2. This process is repeated over and over again, until nT is reached. The forward and backward pressures in each section, will change from sample to sample. The forward wave at the mouth end, e.g. P+(9) for a nine-section model, will model the sound wave coming out of the mouth.
References
Kelly, J. L. Jr. and C. C. Lochbaum (1962) Speech Synthesis. In Proceedings of the Stockholm Speech Communication Seminar. Reprinted in J. L. Flanagan and L. R. Rabiner, eds. (1973) Speech Synthesis. Stroudsberg, PA: Dowden, Hutchinson and Ross. 127-130.
Linggard, R. (1985) Electronic Synthesis of Speech. Cambridge University Press. 61-4.