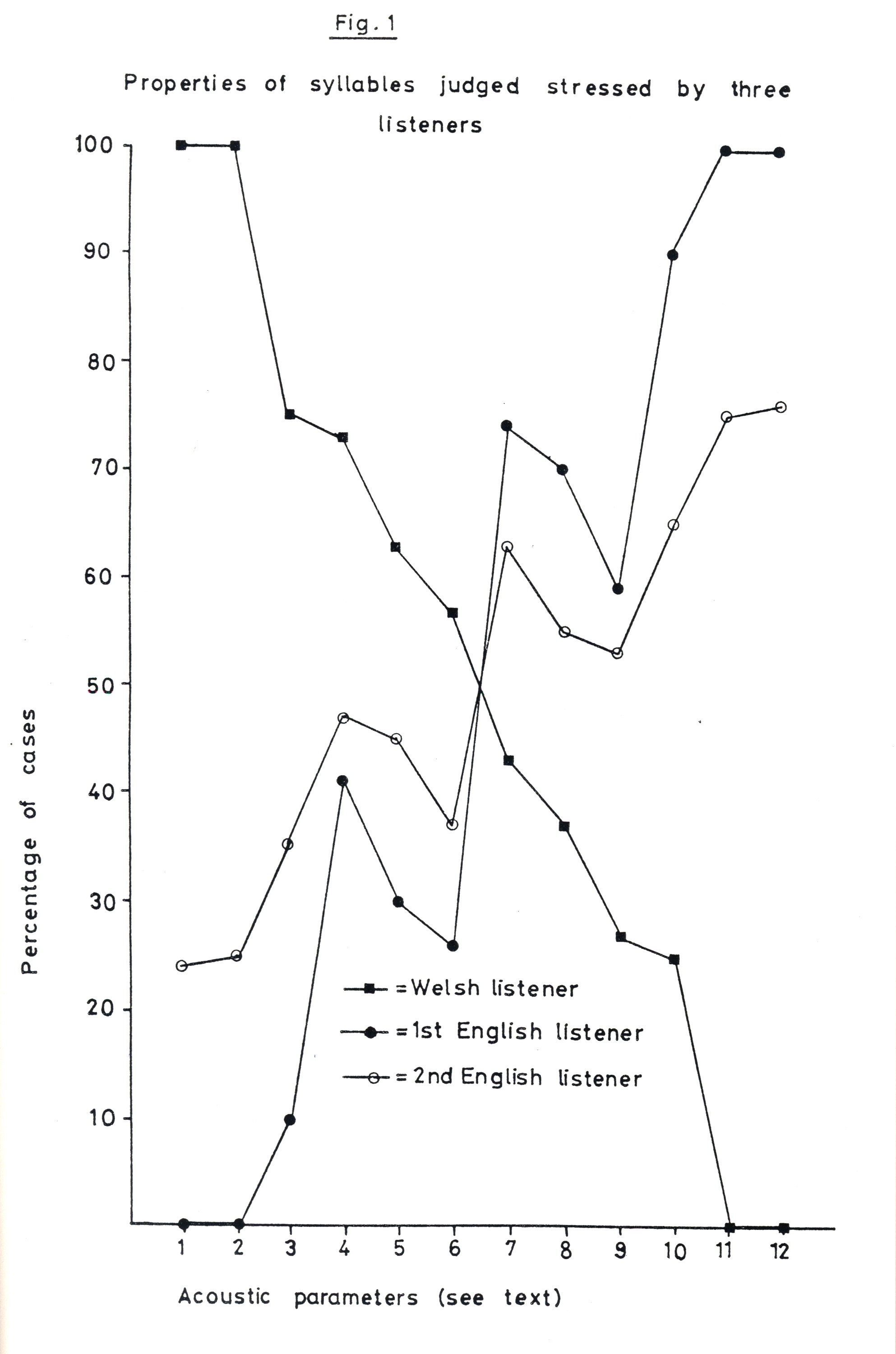
It can be seen from this figure that Welsh vs. English speakers seem to associate quite opposite acoustic features with stress; in particular, syllables perceived as stressed by Welsh listeners have shorter vowels, lower amplitude within the vowel, monotonous pitch (i.e. no pitch movement) on the stressed vowel. The shorter vowels of stressed syllables may however be associated with a longer following consonant (Williams 1998: 8). Although stressed syllables in Welsh are not associated with pitch movement or peaks, it has also been noted that final syllables in Welsh are often associated with a pitch peak, despite being unstressed (Buczek-Zawiła 2014).
Given the resource constraints of the time at which it was carried out, Williams's study was based upon a rather small amount of recorded material from a few speakers. In order to test the results against a larger amount of data from more speakers, this term's experiment will be an acoustic investigation of some phonetic correlates of Welsh stress in a set of isolated words (citation forms) as spoken by a larger number of speakers. The data will be drawn from the Paldaruo Speech Corpus (http://techiaith.cymru/data/corpora/paldaruo/?lang=en):
Hypotheses that could be tested:
1. Stressed vowels in Welsh are of shorter duration than unstressed vowels
2. Stressed