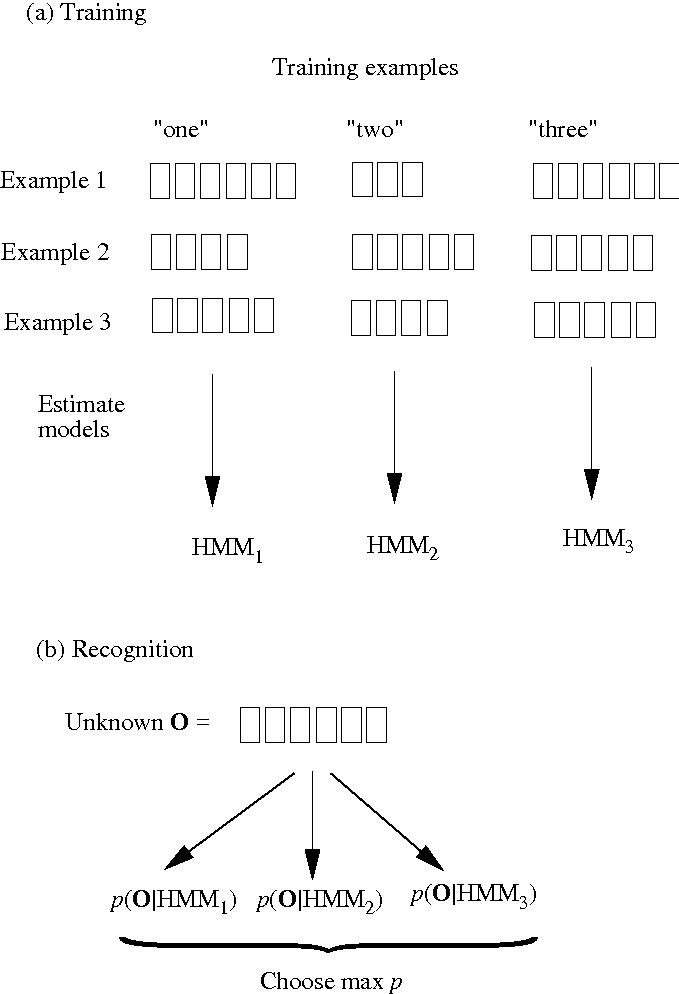
We estimate the hidden parameters (the transition probabilities and the output probabilities) by training the model on a corpus of training examples: that is, recordings of multiple pronunciations of each word. (This is where HMM's improve on, say, DTW-based pattern matching. By virtue of being trained on multiple examples of each word, naturally-occurring variations in the pronunciation of each word can be incorporated.)
The general scheme of training and recognition is shown here.
For isolated word recognition, a separate HMM is built and trained for each word. Recognition, then, is the task of identifying, for a given sequence of input vectors (the observation sequence), which HMM best explains that sequence. So, how does that work?
{kind=link}