Phonetics Laboratory
University of Pennsylvania
| University
of Oxford Phonetics Laboratory
|
|
Linguistic Data
Consortium University of Pennsylvania |
This
project shall address the challenge of providing rich, intelligent data
mining capabilities for
a substantial collection of spoken audio data in American and
British
English. We shall apply and extend state-of-the art techniques to offer
sophisticated, rapid and flexible access to a richly annotated corpus
of a year of speech (about 9000 hours, 100 million words, or 2
Terabytes of speech), derived from the Linguistic Data Consortium, the
British National Corpus, and other existing resources. This is at least
ten times more data than has previously been used by researchers in
fields such as phonetics, linguistics, or psychology, and more than 100
times common practice. (More on the datasets here
...)
It is impractical for
anyone to listen to a year of audio to search for certain words or
phrases, or to
manually analyze the resulting data. With our methods, such
tasks will take just a few seconds. The purposes
for which people conduct such searches are very varied, and it is neither possible nor
desirable to predict what people might want to look for.
Some possibilities are:
Though our experience and research interests happen to be focussed on such matters as intonation, pronunciation differences between dialects, and dialogue modeling, the text-to-speech alignment and search tools produced by the project will open up this "year of speech corpus" for use by a wide variety of researchers interested in e.g. linguistics, phonetics, speech communication, oral history, newsreels, or media studies. Audio-video usage on the Internet is large and growing at an extraordinarily high rate - witness the huge growth of Skype and YouTube (now the second most frequently used search engine in the world). In the multimedia space of Web 2.0, automatic and reliable annotation and searchable indexing of spoken materials would be a "killer app". It is easy to envisage a near-future world in which a search query would return the relevant video clips and data describing the event(s). The techniques we use here could be applied to any material where audio or video is accompanied by a script or transcript, including copyright-controlled broadcast media.
This project has
three stages, in all of which we have considerable experience. Each
stage extends proven technology; their combination and application on a
large scale will open the door to new kinds of language-based research.
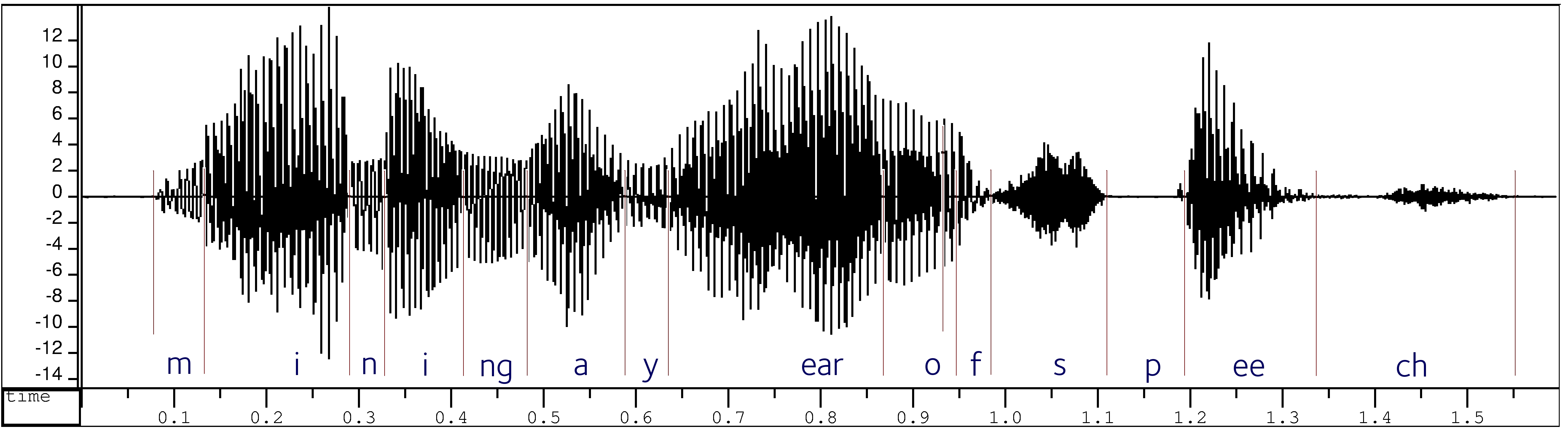
First, we transform transcripts in ordinary spelling into phonetic transcriptions; these are then automatically time-aligned to the digital audio recordings. This uses a version of the forced-alignment techniques developed as part of automatic speech recognition research, adapted to deal with disfluencies and transcripts that are sometimes incomplete or inaccurate.
Second, we put the time-aligned orthographic and phonetic transcriptions into a database that will allow us (or future researchers) to add additional layers of annotation – e.g. marking which meaning of a word is meant – and metadata such as the date and circumstances of the recording. We will also add summaries of acoustic properties that are useful for indexing and data mining.
Third, we will
develop a demonstration front-end for accessing the database. Using
this, we will seek to understand usage scenarios, what data should be
included, and the impact that a larger scale search engine might have.