
People
Papers
Presentations
Audio demonstrations
Indo-European digits database
Events/activities/blog

@ancientsounds@mastodonapp.uk
Audio demonstrations
Here I'll gather together in one place all the audio demos previously posted on the (now closed) twitter feed, on this site's blog, and in presentations and lectures. Check out the blog (see link at left) for more demos and examples.
16-21 July 2020. English "acre" derives from Old English "æcer", via the Great Vowel Shift, and in many UK dialects, "loss" of the final [r]. Here's my audio simulation: phon.ox.ac.uk/jcoleman/RP-ac (or, if your device prefers MP3's, phon.ox.ac.uk/jcoleman/RP-ac)
Old English "æcer" comes from Proto-Germanic *akraz (here sounding more like [akroz] or [akros]), from Post-Proto-Indo-European *aĝros (< PIE *h2eĝros). Audio simulations: (wav) phon.ox.ac.uk/jcoleman/RP-ac (mp3)
Here's another example: (some sort of approximation to) Proto-Indo-European *ĝhwér- > Lithuanian žvėr-inė. Listen: phon.ox.ac.uk/jcoleman/PIE-g, phon.ox.ac.uk/jcoleman/Lithu
23 January 2020."Average pronunciations" (1) Means of a bunch of recordings of French numbers: phon.ox.ac.uk/jcoleman/1to10 (2) Medians of same set of recordings:
14 January 2020. A *laryngeal reflex in Modern Persian: سیاه siyah "black", ultimately from Proto-Indo-European *k̂yeh1-, cognate with English "hue". The final [h] is not a random one-off, but seems common/normal in Iranian Persian, Tajik etc. Listen:
17 December 2019. In May 2015 I posted a simulation of how English "ten" developed from Proto-Indo-European *dekmt (using Lithuanian [dešmt] as proxy). Now, a much better job: ten < Old English tien < Proto-Germanic *tehun < PIE *dekmt. Listen and enjoy:
It's not quite right, because [naɪn] should go through [neɪn] on the way to [ni:n], but this simulation goes via something like [noɪn]. But it's a start.
9
July 2019. Laryngeals in Lithuanian? (a
thread) "raudonas", Lith. for "red", comes from
Proto-Indo-European *h1reudh-; the initial h1 is hypothetical,
based on evidence from several languages. BUT listen to this
first syllable: phon.ox.ac.uk/jcoleman/RUBER
Spectrogram:
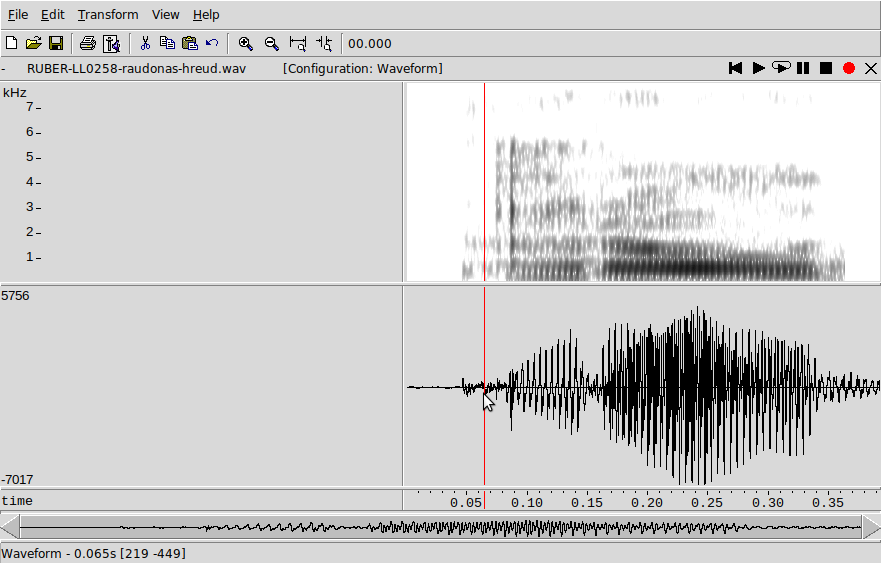
Here's another example of "raudona" from Proto-Indo-European *h1reudh-. Listen to this first syllable: phon.ox.ac.uk/jcoleman/RUBER Downloaded from 50languages.com/phrasebook/les and converted to .wav. Unlike my other demos, these have not been manipulated at all.

I've been looking at tokens of "raudona" today. In most of them, the initial /r/ begins with a little prothetic schwa and then one or two taps [əɾ(ɾ)]. In a minority (~20%?) it's something like [həɾ(ɾ)-], as in the two examples I just posted.
July
24th follow-up, following feedback
from various Twitter commentators:
I
got the LIEPA [Lithuanian corpus] data and have been working
through words beginning with (orthographic) r. The occasional
initial [h]-like frication seems to be pretty random and is
not related to the presumed PIE laryngeals. But still, kind of
interesting.
30 April
2019. VIDEOS!
I've
been making some videos to illustrate processes of sound
change using spectrograms that morph from one into another.
First, here's "te" changing into "se" (which happened in
Balochi): phon.ox.ac.uk/jcoleman/te-to
See the energy rising at the left?
Here's Latin quinque changing into Modern Italian cinque. See the energy rising at the left as the initial plosive morphs into an affricate.
Tip: if any of these video clips don't play properly in your browser (e.g. if you just get a black screen), try saving them to your computer and then opening them with e.g. VLC player
7 December 2018. English
"six" comes ultimately from Proto-Indo-European *kswek̂s, via
[seks].
Listen: http://www.phon.ox.ac.uk/jcoleman/six-from-PIE-ksweks.wav …
Strictly speaking, it should pass through Proto-Germanic *sehs
[sexs]; my version of that came out a bit growly so maybe that's
one for another day ...
6 December 2018. This
has been a while in the making: English "four" is from
Proto-Indo-European "kʷetwóres", via Old English "feower",
Proto-Germanic "fidwor" and Pre-Proto-Germanic "hwidwor". Listen:
http://www.phon.ox.ac.uk/jcoleman/four-from-PIE-kwetwores.mp3 …
(For an easier life, I ignore the -es ending until the very end.)
10 October 2018. English "long" is related to Modern Persian دراز (deraz). "Long" comes from Anglo-Saxon "lang", which came from Proto-Indo-European *dlonghos something like this (I ignore the -os ending), listen:http://www.phon.ox.ac.uk/jcoleman/AS-lang-from-PIE-dlong.mp3 …
Proto-Indo-European
*dlonghos developed into Middle Persian "derang", something like
this:http://www.phon.ox.ac.uk/jcoleman/PIE-dlong-to-MPers-derang.mp3 …
(Obviously we don't have recordings of Middle Persian; this
"derang" is fiddled from a Low German speaker saying "Drang")
Middle Persian
"derang" developed into Modern Persian "deraz", I'm guessing
something like this, listen:http://www.phon.ox.ac.uk/jcoleman/MPers-derang-to-Pers-deraz.mp3 …
The whole sequence from "lang" to "deraz" (with a few pitch
changes along the way):http://www.phon.ox.ac.uk/jcoleman/lang-to-deraz.mp3 …
24 July 2018. Anglo-Saxon
"gōs" came from Proto-Indo-European *ghans (via "gōs" came from
Proto-Indo-European *ghans (via something Germanic "gans"), like
this:http://www.phon.ox.ac.uk/jcoleman/AS-gos-from-PIE-ghans.wav …
mp3: http://www.phon.ox.ac.uk/jcoleman/AS-gos-from-PIE-ghans.mp3 …
29 June 2018. Listen to Latin
"duo" morphing into French "deux"http://www.phon.ox.ac.uk/jcoleman/Latin-duo-to-French-deux.mp3 …
The "duo" recording was disyllabic, much longer than the "deux"
recording, so I compressed it in time to make them the same
length, the best I could manage for now.
28 March 2018. In this thread, we show how the English and Urdu words for "goose" are related.
Modern English
"goose" comes from Anglo-Saxon gōs, like this:
wavs: http://www.phon.ox.ac.uk/jcoleman/Eng-goose-from-AS-gos.wav …
mp3: http://www.phon.ox.ac.uk/jcoleman/Eng-goose-from-AS-gos.mp3 …
Thanks to Prof. Laura Ashe, our voice of Anglo-Saxon.
Anglo-Saxon "gōs"
came from Proto-Indo-European *ghans (via something Germanic
"gans"), like this:
wavs: http://www.phon.ox.ac.uk/jcoleman/AS-gos-from-PIE-ghans.wav …
mps: http://www.phon.ox.ac.uk/jcoleman/AS-gos-from-PIE-ghans.mp3 …
And going
southwards, PIE *ghans developed (eventually) into Urdu "hans",
like this:
wavs: http://www.phon.ox.ac.uk/jcoleman/PIE-ghans-to-Urdu-hans.wav …
mp3: http://www.phon.ox.ac.uk/jcoleman/PIE-ghans-to-Urdu-hans.mp3 …
Thanks to Qurrat for the Urdu recording
11 December 2017. West
meets East: English "fierce" is from Middle English fers, from
Latin fer-us, from Proto-Indo-European *ĝhwēr-
Something like this:http://www.phon.ox.ac.uk/jcoleman/English-fierce-from-PIE-ghwer.wav …
(MP3 version: http://www.phon.ox.ac.uk/jcoleman/English-fierce-from-PIE-ghwer.mp3 …)
(I left out the 2nd vowel in "ferus")
In Iranian,
Proto-Indo-European *ĝhwēr- developed into žver, thence sher (like
in the Jungle Book tiger, Shir Khan). Listen:http://www.phon.ox.ac.uk/jcoleman/PIE-ghwer-to-Persian-shir.wav …
(MP3 version: http://www.phon.ox.ac.uk/jcoleman/PIE-ghwer-to-Persian-shir.mp3 …)
Now it gets
really interesting: Iranianشیر šīr
was borrowed into Chinese and continued to evolve (e.g. to modern
Mandarin shīzi 狮子 'lion'). Listen: http://www.phon.ox.ac.uk/jcoleman/Persian-shir-to-Mandarin-shizi.wav …
(MP3 version: http://www.phon.ox.ac.uk/jcoleman/Persian-shir-to-Mandarin-shizi.mp3 …)
In short, 狮子 is cognate with 'fierce'!
6 December 2017. Grimm's
Law 1a: The initial [b] in English "(to) bear" comes from a voiced
aspirate [bh] in Proto-Indo-European *bher(e/o)-, like this: http://www.phon.ox.ac.uk/jcoleman/PIE-bher-to-Eng-bear.wav …
MP3 version: http://www.phon.ox.ac.uk/jcoleman/PIE-bher-to-Eng-bear.mp3 …
Grimm's Law 1b:
[b] in English "(to) bear" is from a voiced aspirate [bh] in
Proto-Indo-European *bher(e/o)-. Sanskrit "bhar-" retains the
initial [bh]: http://www.phon.ox.ac.uk/jcoleman/PIE-bher-to-Skt-bhar.wav …
(based on recording of @suhasm
saying "bharati")
MP3 version: http://www.phon.ox.ac.uk/jcoleman/PIE-bher-to-Skt-bhar.mp3 …
7 April 2017. In Old and Middle English, "bite" was pronounced more like the modern word "beat". The vowel evolved, like this: http://www.phon.ox.ac.uk/jcoleman/beat-to-bite.wav …
MP3 version of
Middle English "bite" changing to its modern pronunciationhttp://www.phon.ox.ac.uk/jcoleman/beat-to-bite.mp3 …
(The pitch change is irrelevant!)
1 April 2017. (No,
not an April Fool's Day joke!)
For #WhanThatAprilleDay17, a few demos of how English and Persian have a common ancestry in Indo-European.
English "belly" (also "bulge") comes from PIE *bhólĝhis. Irish "bolg" (same root) makes a pretty good proxy: http://www.phon.ox.ac.uk/jcoleman/belly-to-bolg.wav …
MP3 simulation of how "belly" comes from PIE *bhólĝhis (Irish "bolg"): http://www.phon.ox.ac.uk/jcoleman/belly
Persian balish
"pillow" is also from PIE *bhólĝh-http://www.phon.ox.ac.uk/jcoleman/balesh-to-bolg.wav …
MP3: http://www.phon.ox.ac.uk/jcoleman/balesh-to-bolg.mp3 …
Like Persian balish بالش, Slovenian "blazina" (both mean "pillow") is also from PIE *bhólĝh-http://www.phon.ox.ac.uk/jcoleman/blazina-Slovenian.wav …
A borough (Old English burh) is a fortified town, from PIE *bherĝhs, "high place": http://www.phon.ox.ac.uk/jcoleman/borough-to-bergs.wav …
MP3 version: http://www.phon.ox.ac.uk/jcoleman/borough-to-bergs.mp3 …
Also from PIE *bherĝhs, "high place": Armenian bardzr, Pers. borz, Balochi borza, Russ béreg, Ir. brí, Gk. púrgos ...
Here's Persian
"borz" evolving from (sort of) PIE *bherĝhs http://www.phon.ox.ac.uk/jcoleman/borz-to-bergs.wav …
MP3: http://www.phon.ox.ac.uk/jcoleman/borz-
28 October 2016. Today's experiment: Proto-Indo-European *bhreĝ, 'break' http://www.phon.ox.ac.uk/jcoleman/PIE-bhreg.wav …
Modern English 'break' comes from Proto-Indo-European *bhreĝ something like this: http://www.phon.ox.ac.uk/jcoleman/break-from-bhreg.wav …
23 October
2015. Previously
I posted demo of "five" from (Lithuanian) "penki". But
PIE has *penkwe, not penki. So here done better: http://www.phon.ox.ac.uk/jcoleman/five-from-penkwe.mp3 …
Starting to fill new table of Indo-European digit sounds at http://www.phon.ox.ac.uk/jcoleman/ancient-sounds-database.html … New tokens of *treies, *ksweks, quinque and Ancient Gk, and *penkwe, *septm (wrong stress, but hey), quattuor (hybrid of Ladin kwater and Welsh pedwar, maybe too prominent). Comments +/- welcomed.
11 August
2015. Clips relating to the paper we
gave at the 18th International Congress of
Phonetic Sciences, Glasgow
(Coleman, Aston and Pigole 2015, "Reconstructing the sounds
of words from the past"), is available from the "papers"
page (see sidebar at left).
- the [u:n] sound of Italian or Spanish uno as a plausible proxy for the sound of un- in Latin ūnus
- the acoustic-historical path from Latin [u:n-] via Portuguese [ũ]
- to French [œ̃]
- thence to the more recent French pronunciation [ε̃]
- The acoustic-historical path from Latin [u:n-] to the more recent French pronunciation [ε̃]
- the older and more conservative French form [œ̃]
- The continuum from Italian [due] to French [dœ]
- Monophthongisation illustrated by the continuum from Spanish [seis] to French [sis]
- and diphthongisation by Spanish [dos] to Brazilian Portuguese [dois]
- The development from final [-s] to [-ʃ] after [i] in (Standard) Portuguese illustrated by Spanish [tres] → Portuguese [treiʃ]
- Spanish [seis] → Portuguese [seiʃ]
- Postalveolarization plus affrication is also seen in e.g. French [set] → Portuguese [setʃ]
- and Italian [ot:o] → Spanish [otʃo]
26 May 2015. "Three" comes from Proto-Indo-European "*treyes". Not from Spanish "tres", but that's the nearest I've got. Listen: http://www.phon.ox.ac.uk/jcoleman/three-from-treis.wav. Here's the MP3 version: http://www.phon.ox.ac.uk/jcoleman/three-from-treis.mp3 …
25 May 2015. "One" comes from Proto-Indo-European *oinos, via Middle English "oon", Anglo-Saxon "an", Germanic "oin(s)". Listen: http://www.phon.ox.ac.uk/jcoleman/one-from-oins.wav …
"One" from "oin(s)", MP3 format: http://www.phon.ox.ac.uk/jcoleman/one-from-oins.mp3 …
Previously [12th May] we generated a continuum of sounds from "two" to "twa" and vice-versa. Now, we follow "two" all the way back to Proto-Indo-European *dwo(H). WAV: http://www.phon.ox.ac.uk/jcoleman/two-from-dwo.wav … MP3: http://www.phon.ox.ac.uk/jcoleman/two-from-dwo.wav.mp3 …
“Nine” is from
Proto-Indo-European *h1newh1m (әnewәm) via [niin],
[neɣn] Listen: http://www.phon.ox.ac.uk/jcoleman/nain-from-neGn.wav … or http://www.phon.ox.ac.uk/jcoleman/nain-from-neGn.mp3 ….
20 May 2015. English "ten" comes via tene, teihen from Proto-Indo-European *dekmt (my nearest recording is Lithuanian [dešmt]): http://www.phon.ox.ac.uk/jcoleman/ten-from-deshmt.wav …
18 May 2015. "Eight" came from Proto-Indo-European *Hokto, via changes something like this: http://www.phon.ox.ac.uk/jcoleman/eight-from-okto.wav … (MP3 version http://www.phon.ox.ac.uk/jcoleman/eight-from-okto.mp3 …)
15 May
2015. "Eight" comes
from "aehta" (but I ignore the final vowel for now): http://www.phon.ox.ac.uk/jcoleman/eight-from-aeht.wav
15 May 2015. "Four" comes from Anglo-Saxon "feower": http://www.phon.ox.ac.uk/jcoleman/four-from-feower.wav …
15 May 2015.
"Five" comes via fif, fimf, pemp from Proto-Indo-European *penkwe.
Lithuanian penki is nearest living word. Listen: http://www.phon.ox.ac.uk/jcoleman/five-from-penki.wav …
12 May 2015. Simulating the derivation of Modern English "two" from Anglo-Saxon "twa": http://www.phon.ox.ac.uk/jcoleman/two-from-twa.wav … Or if you prefer going forwards in time from Anglo-Saxon "twa" to Modern English "two": http://www.phon.ox.ac.uk/jcoleman/twa-to-two.wav …
1 April 2015.
For #WhanThatAprilleDay15, we made a "Sonic
Time Machine": http://www.phon.ox.ac.uk/jcoleman/sonic2.html … to
show Anglo-Saxon pronunciations (or something close to them)
that survived until quite recently in various German dialects.
